Post-procesado de cadenas de Markov
Los métodos tradicionales de post-procesado de cadenas de simulación, basados en técnicas como burn-in y thinning, son demasiado arbitrarios para poder parametrizarlos de forma automática sin intervención del usuario. Además no solucionan uno de los principales problemas de los métodos accept-reject con generadores de candidatos sobre paseos aleatorios, que es la alternacia de fases con exceso de repeticiones por usar un tamaño de paso demasiado grande, con otras fases en las que, por todo lo contrario, se avanza poco en cada iteración. En ambos casos se producirán zonas hipermuestreadas.
 | 
|
| Fig 1: Tamaño de paso demasiado grande | Fig 2: Tamaño de paso demasiado pequeño |
Las siguientes gráficas se refieren a una simulación de Metropolis-Hastings de una binormal, a la cual llamaremos EjMcmc01

Fig 3: [EjMcmc01] Vista parcial del periodo de convergencia inicial

Fig 4: [EjMcmc01] Cadena completa vista como scatter bidimensional

Fig 5: [EjMcmc01] La cadena completa (abajo) junto a los valores de la función de densidad (arriba)
| En la gráfica anterior se observa cómo de vez en cuando la cadena se hace demasiado repetitiva y luego vuelve a recobrar el comportamiento esperado y eso que se trata de una simple binormal. Cuando la función de densidad es muy complicada, demasiado no lineal o hay altas correlaciones se pueden producir todo tipo de fenómenos inesperados en cualquier lugar de las cadenas de Markov que pueden desvirtuar las inferencias que de ella se extraigan . Otra situación habitual es que los algoritmos pasan por un periodo de convergencia, normalmente al principio de la cadena, pero podría ocurrir en más ocasiones y entonces la técnica burn-in no es aplicable. Pero incluso cuando sólo ocurre al principio no es trivial establecer el número de muestras a eliminar. Tampoco existe ninguna forma trivial de aseverar que una cadena de Markov ha recorrido el dominio de la distribución de forma suficbientemente exhaustiva, es decir, de asegurar que no hay lagunas inframuestreadas. Las cadenas simuladas con BysSampler cuentan con una ventaja adicional al conocerse el logaritmo de la verosimiltud de cada punto muestral, salvo una constante aditiva, pues esto permite contrastarla directamente con la masa local empírica, es decir el número de puntos que han sido generados en sus cercanías. En una cadena perfectamente muestreada el número de puntos generados en torno a un punto dado debería ser proporcional a la verosimilitud media alrededor de dicho punto. Esto permite diseñar un criterio completamente objetivo para eliminar puntos de zonas supoerpobladas e incluso sustituirlos por puntos en otras zonas inframuestreadas. En la gráfica de la derecha se observa muy claramente que hay demasiados puntos con muy poca probabilidad, y lo que se pretende aquí es crear un sistema que sea capaz de detectar y subsanar este tipo de problemas para cualquier número de dimensiones. |  Fig 6: [EjMcmc01] Función de densidad (salvo una constante) de la cadena de Markov anterior |
Diseño de entornos locales solapados
Buscamos una forma de contrastar la proporción respecto del total de los puntos que hay en una zona determinada del espacio recorrido con la probabilidad de esa zona correspondiente a la función de densidad que es conocida en cada punto de la muestra, y queremos hacerlo para cualquier zona analizada. Evidentemente esto es demasiado abstracto para ser implementado y hay que concretar qué tipo de zonas queremos contrastar, qué forma y qué tamaño deben tener y cómo construirlas de forma que efectivamente abarquen todo el espacio objetivo.
El método propuesto comenzará por utilizar el algoritmo KNN que está disponible dentro del paquete TOL MatQuery, para encontrar los vecinos más próximos de cada punto de la muestra de tamaño 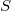 de una forma muy eficiente. Concretamente la librería que se usa es Approximate Nearest Neighbor Searching (ANN) de David M. Mount and Sunil Arya. Esto nos permitirá definir entornos esféricos centrados en cada uno de los puntos de la muestra, lo cual asegura la cobertura total de la muestra sin ningún género de dudas.
de una forma muy eficiente. Concretamente la librería que se usa es Approximate Nearest Neighbor Searching (ANN) de David M. Mount and Sunil Arya. Esto nos permitirá definir entornos esféricos centrados en cada uno de los puntos de la muestra, lo cual asegura la cobertura total de la muestra sin ningún género de dudas.
Como en los métodos de simulación tipo accept-reject hay por definición puntos repetidos, para que el algoritmo tenga sentido habría que tomar los 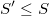 puntos únicos
puntos únicos
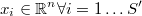
y llamar
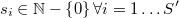
al número de veces que aparece cada uno en la muestra. Obviamente, la suma de los números de apariciones da el tamaño muestral
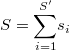
 Fig 7: Entorno de 7 vecinos | No está claro por el momento cuál podría ser el criterio para seleccionar el número  de vecinos en cada entorno, pero debe ser en cualquier caso un número bastante pequeño en relación con de vecinos en cada entorno, pero debe ser en cualquier caso un número bastante pequeño en relación con  pues se trata de observar el comportamiento a nivel local. pues se trata de observar el comportamiento a nivel local.También ha de ser bastante pequeño en términos absolutos porque la complejidad del algoritmo KNN crece cuadráticamente con el tamaño del vecindario. No puede ser excesivamente pequeño porque entonces quedarían amplias zonas del espacio sin recubrir por no estar lo suficientemente cerca de ninguno de los puntos muestreados. Lo ideal sería tomar un sistema de entornos que recubriera de forma conexa y compacta la muestra, aunque eso no parece facil de comprobar a primera vista. No es en principio obligatorio tomar el mismo número de puntos en cada entorno aunque por el momento supondremos que es así. |
Sean los puntos muestrales vecinos de 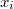 en orden de proximidad al mismo
en orden de proximidad al mismo
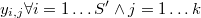
Por extensión diremos que un punto es su propio vecino
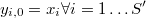
y diremos que hay 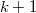 vecinos distintos en cada entorno.
vecinos distintos en cada entorno.
Sea la distancia euclídea del punto a su 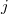 -ésimo vecino más próximo
-ésimo vecino más próximo
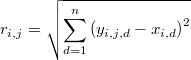
Para no favorecer sesgos tomaremos la distancia intermedia entre el -ésimo vecino y el siguiente como radio del entorno
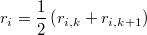
de forma que todo los puntos sean extrictamente interiores al mismo
En cada punto muestral definiremos pues el entorno local como la hiperesfera de radio 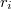 y centro
y centro
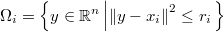
Se trata de ver qué entornos están hipermuestreados y cuáles están inframuestreados, para lo cual deberemos estudiar la distribución de probabilidad del tamaño muestral incluido dentro de cada uno.
Distribución del tamaño muestral local
En una muestra aleatoria perfecta de la función de distribución, cada punto generado es independiente de los demás y la probabilidad de que caiga precisamente en LatexEquation( \Omega_{i} )]] es la integral de la función de densidad en dicho entorno local
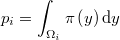
El tamaño muestral local, es decir, el número total de puntos muestrales en 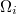 , es
, es
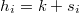
cantidad que se distribuye evidentemente como una binomial
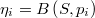
La esperanza del tamaño muestral local es
![E\left[h_{i}\right]=Sp_{i}](../chrome/site/images/latex/f8b81f161093f15ec750c424edbbf86b.png)
Aproximación de la probabilidad del entorno local
La anterior integral sería algo muy costoso de evaluar así que hay que aproximarla por el método de Montecarlo, como el producto del volumen de la hiperesfera
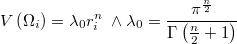
por la media de las verosimilitudes en una selección de puntos del entorno
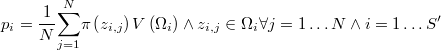
El error en este tipo de aproximaciones decrece proporcionalmente a la raíz del número de puntos en el que evaluamos la verosimilitud pero sólo tenemos puntos interiores. Por otra parte tampoco conocemos la verosimilitud sino una función porporcional a la misma. Es decir, lo único que conocemos sin coste adicional es el logaritmo de la verosimilitud, salvo una constante 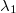 desconocida, evaluado en cada uno de los puntos muestrales, es decir, conocemos
desconocida, evaluado en cada uno de los puntos muestrales, es decir, conocemos
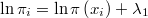
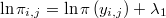
| Como evaluar la función demasiadas veces podría ser muy costoso la única forma de mejorar la aproximación de la integral es por interpolación, concretamente mediante el método de Sheppard de ponderación inversa a la distancia que es muy eficiente pues no requiere de ninguna evaluación extra. Esto es especialemente recomendable si existen grandes diferencias en las verosimilitudes de los distintos puntos del vecindario. La interpolación será mejor realizarla en términos logarítmicos pues eso suavizará la función. Para ello generaremos 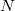 puntos con distribución uniforme en la hiperesfera puntos con distribución uniforme en la hiperesfera y calculamos la aproximación del logaritmo de la verosimilitud en cada uno de ellos mediante la fórmula de ponderación de Sheppard |  Fig 8: Entorno de 7 vecinos y 78 puntos de aproximación |
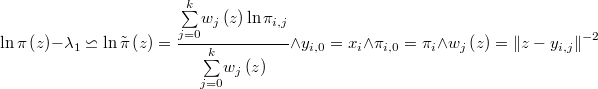
Si el número de puntos básicos de la interpolación 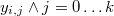 , es demasiado pequeño se puede ampliar con sus vecinos, los vecinos de sus vecinos y así sucesivamente hasta que haya suficientes puntos básicos distintos. Gracias al algoritmo KNN realizado anteriormente esto no supondrá apenas ningún sobrecoste. Durante los propios procesos de generación se evalúan puntos que se rechazan o que se utilizan de forma auxiliar y que se podrían almacenar fuera de la cadena para utilizarlos comjo puntos básicos de esta aproximación.
, es demasiado pequeño se puede ampliar con sus vecinos, los vecinos de sus vecinos y así sucesivamente hasta que haya suficientes puntos básicos distintos. Gracias al algoritmo KNN realizado anteriormente esto no supondrá apenas ningún sobrecoste. Durante los propios procesos de generación se evalúan puntos que se rechazan o que se utilizan de forma auxiliar y que se podrían almacenar fuera de la cadena para utilizarlos comjo puntos básicos de esta aproximación.
Nos queda finalmente la fórmula de aproximación
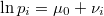
en la que llamaremos constante de integración a 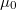 , que es un valor desconocido a estimar. La parte conocida
, que es un valor desconocido a estimar. La parte conocida 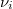 es el logaritmo de la media de las verosimilitudes interpoladas más el logaritmo del volumen salvo la constante
es el logaritmo de la media de las verosimilitudes interpoladas más el logaritmo del volumen salvo la constante 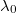 que aunque es conocida es irrelevante. De hecho es conveniente sumarle a otra constante
que aunque es conocida es irrelevante. De hecho es conveniente sumarle a otra constante 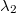 que obligue a que su máximo sea 0 y evitar así problemas numéricos con las exponenciales
que obligue a que su máximo sea 0 y evitar así problemas numéricos con las exponenciales
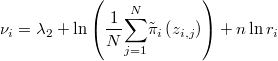
Es decir, hay que tomar
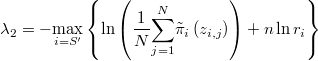
para que resulte
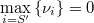
Acotación de la constante de itegración
Puesto que una probabilidad ha de ser menor que 1 su logaritmo es siempre negativo, por lo que tenemos una cota para la constante
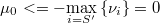
Podemos obtener un valor aproximado teniendo en cuenta que la esperanza de la suma de los tamaños muestrales observados es conocida
![E\left[\underset{i=1}{\overset{S'}{\sum}}h_{i}\right]=\underset{i=1}{\overset{S'}{\sum}}Sp_{i}=\underset{i=1}{\overset{S'}{\sum}}Se^{\mu_{0}+\nu_{i}}](../chrome/site/images/latex/c84df22bbbe9b24c3c8d77cd006877f8.png)
de donde se extrae que
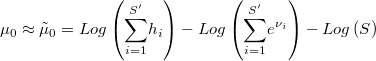
Sin embargo, esta aproximación sólo es adecuada para muestras exactas, y puesto que existen serias sospechas sobre exceso de repeticiones y lagunas inframuestreadas, es posible que necesitemos un criterio más robusto para establecer cuál debe ser el valor de la constante . Dado que conocemos la forma de la distribución podemos encontrar su valor máximo-verosímil. Lo que sí es posible hacer es utilizar la anterior aproximación para establecer un buen intervalo para el algoritmo de optimización que es algo que facilita mucho el trabajo. (Pendiente de desarrollo)
Estimación de la constante
La probabilidad de que el número de puntos que caen dentro de la hiperesfera sea exactamente 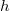 para la binomial definida anteriormente es
para la binomial definida anteriormente es
![P_i = \mathrm{Pr}\left[\eta_{i}=h_{i}\right]=\left(\begin{array}{c}S\\h_{i}\end{array}\right)p_{i}^{h_{i}}\left(1-p_{i}\right)^{S-h_{i}}](../chrome/site/images/latex/5d1b68d3735d875b88efd989c29df9d7.png)
y el logaritmo de dicha probabilidad será
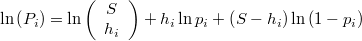
La verosimilitud de 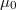 dada la muestra observada, bajo la hipótesis de independencia entre los distintos entornos, será proporcional al productorio de las probabilidades del número de puntos efectivamente encontrados en cada uno. La expresión de su logaritmo será la siguiente
dada la muestra observada, bajo la hipótesis de independencia entre los distintos entornos, será proporcional al productorio de las probabilidades del número de puntos efectivamente encontrados en cada uno. La expresión de su logaritmo será la siguiente
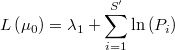
en la que la constante desconocida es irrelevante.
En realidad los entornos cercanos no pueden ser independientes entre sí, pues de hecho comparten puntos, pero en primera instancia daremos por buena la hipótesis de independencia, simplemente por comodidad y porque no está claro que sea demasiado importante el efecto de la dependencia.
Así pues tendremos el problema de optimización univariante
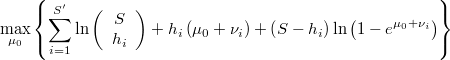
Sujeto a
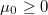
Resolviendo este problema obtenemos el valor de que nos permite completar el resto de cálculos.
Función de distribución
La probabilidad de que el número de puntos que caen dentro de la hiperesfera sea mayor o igual que se calcula mediante la función beta incompleta
![\mathrm{Pr}\left[\eta_{i}\leq h_{i}\right]=I_{1-p_i}\left(S-h_{i},h_{i+1}\right)](../chrome/site/images/latex/4979a8ddd15ba42b6915e3f3f6691956.png)
En virtud de la propiedad de simetría
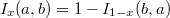
se obtiene la fórmula alternativa
![\mathrm{Pr}\left[\eta_{i}\geq h_{i}\right]=I_{p_{i}}\left(h_{i+1},S-h_{i}\right)](../chrome/site/images/latex/dec51ff837f79521f8e1a1210374c507.png)
Cada una de las fórmulas alternativas será más precisa cuando se acerca a 0, es decir, la primera es mejor en la cola izquierda y la segunda en la derecha.
Estrategia de post-procesado
Una vez conocida la distribución del tamaño muestral local hay que contrastarlo con el valor observado y eliminar puntos en las zonas donde sobran y añadir en aquellas en las que faltan. No tiene porqué tratarse de un trasvase de suma 0, sino que puede forzarse que el tamaño muestral final 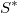 sea menor o mayor que el inicial , según sean los intereses del usuario que será quien lo especifique. Habrá situaciones, como en modelos de tamaño moderado, en las que primará la precisión y se deseará aumentar la muestra, y otras en las que por el excesivo tamaño o por la masividad del número de modelos habrá que restringir el volumen de información para ajustarse a los recursos de memoria y tiempo disponibles. En este caso, el sistema actuará como un sistema de compresión con pérdida de información mínima.
sea menor o mayor que el inicial , según sean los intereses del usuario que será quien lo especifique. Habrá situaciones, como en modelos de tamaño moderado, en las que primará la precisión y se deseará aumentar la muestra, y otras en las que por el excesivo tamaño o por la masividad del número de modelos habrá que restringir el volumen de información para ajustarse a los recursos de memoria y tiempo disponibles. En este caso, el sistema actuará como un sistema de compresión con pérdida de información mínima.
Para evitar parámetros más o menos arbitrarios o difíciles de calibrar se puede seguir un mecanismo iterativo que filtre y colonize en cada etapa bajo condiciones muy restrictivas, es decir, allí donde no quepa duda alguna que debe intervenirse. Tras cada etapa se calculan una serie de cuantiles sobre cada variable escalares y se para si no se perciben cambios significativos para una tolerancia dada.
En las sucesivas fases no sería preciso repetir todos los cálculos pues los algoritmos de búsqueda de vecinos permiten la inserción y borrado de puntos de forma eficiente.
Filtrado de zonas hipermuestreadas
En los entornos en los que la probabilidad de exceso de muestra sea muy alta
![\mathrm{Pr}\left[\eta_{i}\leq h_{i}\right] \geq 1-\alpha_1](../chrome/site/images/latex/72d559fd2bad3df6763efb49ce95e22d.png)
habrá que eliminar puntos, empezando por los repetidos, hasta que se entre dentro de un margen razonable.
Por razones numéricas es más conveniente chequear esta desigualdad equivalente:
![\mathrm{Pr}\left[\eta_{i}\geq h_{i}\right] \leq \alpha_1](../chrome/site/images/latex/5ccf01e1abbd801bf97621433dfe3117.png)
(Pendiente de desarrollo)
Colonización de zonas infreamuestreadas
En los entornos en los que la probabilidad de defecto de muestra sea muy alta
![\mathrm{Pr}\left[\eta_{i}\geq h_{i}\right] \geq 1-\alpha_2](../chrome/site/images/latex/c9d9e0f1326504ef446ee2f332b730c6.png)
habrá que añadir más mediante un mecanismo que asegure la convergencia.
Por razones numéricas es más conveniente chequear esta desigualdad equivalente:
![\mathrm{Pr}\left[\eta_{i}\leq h_{i}\right] \leq \alpha_2](../chrome/site/images/latex/ce895b999a734ce4e92443b1178f8e6a.png)
Una posibilidad sería continuar el mismo método utilizado en la generación de la muestra analizada comenzando por los puntos centrales de los entornos más despoblados hasta compensar la masa faltante. Pero dada la información acumulada sería quizás más razonable utilizar un generador de candidatos con media en los puntos centrales en lugar de usar un paseo aleatorio. Incluso se podría usar el método de ensayo múltiple generalizado usando como precandidatos los mismos puntos generados anteriormente para la aproximación de la integral.
(Pendiente de desarrollo)