BysVecLinReg
BysVecLinReg is an open source TOL Package published as partt of Official Tol Archive Network
BysVecLinReg yields for Bayesian simulator of Vectorial Linear Regression with arbitrary constraining inequations and lineal constraining equations.
The method used to solve it in this package is based on
Bayesian linear regression Thomas Minka (2001) using invariant scale prior over
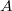 and inverse prior over
and inverse prior over 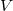
Vectorial linear regression
Vectorial linear regression equations are
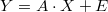
where
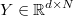 is the multivariant known
output matrix, where each row is a different output vector
is the multivariant known
output matrix, where each row is a different output vector
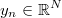
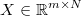 is the known and full rank
input matrix, where each row is a different input vector
is the known and full rank
input matrix, where each row is a different input vector
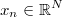
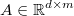 has the unknown regression
coefficients that we want to estimate
has the unknown regression
coefficients that we want to estimate
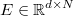 is the multivariant
residuals, where each row is the residuals vector
is the multivariant
residuals, where each row is the residuals vector
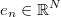 corresponding to output
corresponding to output
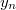
All residuals inside the same row are incorrelated normal, but resiudals in
the same column 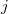 are
are
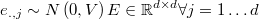
where is symmetric positive definite and unknown, but the
same for each column.
Minka defines also the known data pair 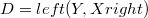 that will be used just to get more compact conditioninig expressions.
that will be used just to get more compact conditioninig expressions.
Arbitrary constraining inequations
We will extend the model scope with arbitrary non null meassured restrictions
over parameters inside by means of adding a set of
 inequations defining a feasible region
inequations defining a feasible region
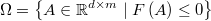
being
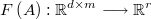
the arbitrary constraining function.
Invariant-scale prior over coefficient matrix
Although Minka not explicitly stated in any place, under the invariant prior
follows that 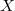 must be full-rank
must be full-rank 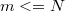 because
because 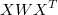 must be nonsingular with
must be nonsingular with
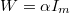 , where
, where 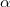 is the
scale-invariant parameter governing the prior and estimated more
forward to maximize the evidence of the data, which depends on the assumptions
the model.
is the
scale-invariant parameter governing the prior and estimated more
forward to maximize the evidence of the data, which depends on the assumptions
the model.