| Version 19 (modified by , 15 years ago) (diff) |
|---|
Package GrzLinModel
Max-likelihood and bayesian estimation of generalized linear models with scalar prior information and constraining linear inequations.
Weighted Generalized Regresions
Abstract class
GrzLinModel::@WgtReg
is the base to inherit weighted generalized linear regressions as poisson,
binomial, normal or any other, given just the scalar link
function 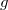 and the density function
and the density function 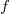 .
.
In a weighted regression each row of input data has a distinct weight in the likelihood function. For example, it can be very usefull to handle with data extrated from an stratified sample.
Let be
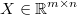 the regression input matrix
the regression input matrix
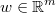 the vector of weights of each register
the vector of weights of each register
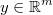 the regression output matrix
the regression output matrix
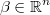 the regression coefficients
the regression coefficients
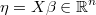 the linear prediction
the linear prediction
- the link function
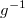 the inverse-link or mean function
the inverse-link or mean function
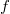 the density function of a distribution of the
exponential family
the density function of a distribution of the
exponential family
Then we purpose that the average of the output is the inverse of the link function applyied to the linear predictor
![E\left[y\right]=\mu=g^{-1}\left(X\beta\right)](../chrome/site/images/latex/d736afbc8c203accc120e24254ad91ba.png)
The density function becomes as a real valuated function of at least two parameters
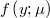
For each row 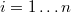 we will know the output
we will know the output 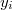 and the average
and the average
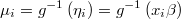
Each particular distribution may have its own additional parameters which will be treated as a different Gibbs block and should implement next methods in order to be able of build both bayesian and max-likelihood estimations
- the mean function:
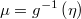
- the log-density function:
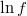
- the first and second partial derivatives of log-density function respect to the linear prediction
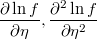
The likelihood function of the weigthed regression is then
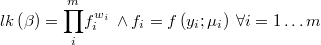
and its logarithm
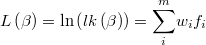
The gradient of the logarithm of the likelihood function will be
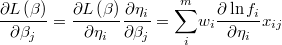
and the hessian is
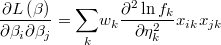
This class also implements these common features
- scalar prior information of type normal or uniform, truncated or not in both cases, and
- linear constraining inequations over linear parameters
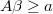
Weighted Normal Regresion
Is implemented in GrzLinModel::@WgtNormal There is a sample of use in test_0001/test.tol
In this case we have
- the identity as link function and mean function
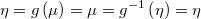
- the density function has the variance as extra parameter
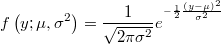
- the density function will be then
- the log-density function will be then
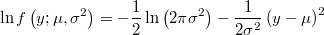
- the partial derivatives of log-density function respect to the linear prediction is
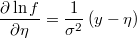
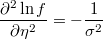
Weighted Poisson Regresion
It will be implemented in GrzLinModel::@WgtPoisson but is not available yet.
In this case we have
- the link function
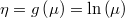
- the mean function
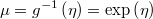
- the probability mass function
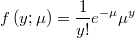
- and its logarithm will be
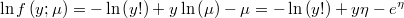
- the partial derivatives of log-density function respect to the linear prediction is
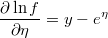
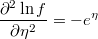
Weighted Qualitative Regresion
For boolean and qualitative response outputs like logit or probit there is an specialization on package QltvRespModel